Il est notoirement connu que le cerveau humain a des capacités de reconnaissance des formes qui sont bien plus développées que ce que sait faire un programme d’ordinateur. Cela explique pourquoi les taux d’échec des programmes d’OCR (Optical Character Recognition) sont aussi élevés que 1% (ou parfois 2%) d’erreur, soit un niveau qui impose de fournir une relecture humaine derrière la plupart des scans de documents. Mais quand le document est ancien, de mauvaise qualité d’impression, dégradé, les taux d’erreur peuvent être encore plus élevés et posent des problèmes considérables quand il s’agit de scanner des milliers de documents comme le font certaines bibliothèques et institutions culturelles.
Par ailleurs, le problème du SPAM sur Internet est considérable : des programmes essayent à tout prix de se faire passer pour des êtres humains afin d’insérer de la publicité partout où un utilisateur peut écrire (dans les messages d’un forum, dans les commentaires d’un blog, etc.) Depuis quelques temps, il est devenu courant qu’un être humain doivent s’identifier comme humain par sa capacité à reconnaître un mot plus ou moins bien écrit/dessiné. Théoriquement, c’est un test de Turing efficace qui permet de différencier un humain d’une machine. En pratique, les compétences d’un programme automatique sont tout de même devenues telles que le SPAM ré-apparaît doucement dans les environnements même protégés par ce qu’on appelle les CAPTCHA (ces images qu’il s’agit de lire et de recopier pour pouvoir être autorisé à une action).
Le problème est ainsi posé : créer des CAPTCHA vraiment très difficiles à reconnaître par programme et, simultanment, utiliser des êtres humains pour scanner des documents très difficiles à lire par les programmes.
La solution : reCAPTCHA.
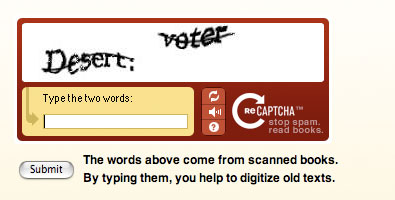
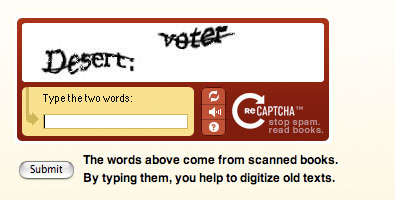
Il s’agit de fournir un service de type CAPTCHA à des milliers de blogueurs et de gestionnaires de forum (WordPress, phpBB, etc.) Les utilisateurs sont invités à reconnaître deux mots particulièrement difficiles à reconnaître visuellement (les programmes d’OCR professionnel y ont échoué lors de scan tentés par Carnegie Mellon University). L’utilisateur doit les reconnaître tous les deux. L’un sert à vérifier si c’est bien un utilisateur humain, l’autre à donner la traduction OCR qui enrichira la base de CAPTCHA pour le futur et qui améliorera le scan d’un document en cours de traitement par Carnegie Mellon. C’est le double effet K… : lutte contre les spammeurs et mise à disposition de millions d’être humains pour améliorer le scan de milliers de documents anciens (sans même recourir à l’esclavage de masse).
Example de scan difficile à reconnaître :

Une particularité des logiciels professionnels d’OCR est qu’ils sont presque toujours capables de signaler quand leur reconnaissance est impossible ou de très mauvaise qualité (grande incertitude).