While I understand a few languages (French is my mother language, English and Spanish are OK, Portuguese or Italian I can recognize most of it), in my professional life, I have to handle a huge number of written comments in many different languages from all over the world (verbatim comments given by end-users and repair technicians, in a warranty data system for cars). It means that I am regularly confronted with one of the ugliest situations in translation:
- Many languages at the same time (most of which I do not know),
- Short-hand annotations, and imprecise wording from people not always familiar with the technical field,
- Database field entries which may have been botched down by inappropriate input methods or bad text transfer from a database to another.
However, I have to admit that a positive aspect is that I (and the team I’m working with) have good knowledge of the technical issues we encounter most often (it’s amazing how electronic car parts fail always the same way).
So, I had to develop a set of tools and methodologies to solve most of the issues found here and I thought that you may want to hear about them (at least, I thought of sharing that knowledge with you).
Raw text
The first issue I often encounter is the presence of badly formed raw text. It’s not readable at all, even by somebody whose mother language is used in the text. For example, we may find “text” like:
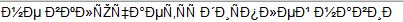
And we have to understand that what was actually typed by the original writer was:
%20

This comes from very bad handling of international text (non-Latin text using characters more complex than the usual 7-bit ANSI/ASCII character set A-to-Z and a-to-z). Rather than complain, I found the Branah.com web site, hosting a very useful anything-into-anything convertor, where I just have to more or less recognize the appearance of the garbled data (the example lines that you can see in the photo below, will be an appreciated help here) and it will get translated into useful text.
Quick translation
Then, the text should be actually translated. I could ask a Russian to translate Russian text for me. But what when I have Russian, Hungarian, Polish, Slovakian, Bulgarian, Romanian, Korean, Japanese, etc. in the same job list? It’s better to speed up the process with Google Translate.
For sure, Google is not perfect. But for many languages, it’s providing a relatively good translation (remember that I’m not trying to get a great literary novel printed in a new foreign language).
A few of the tricks from Google Translate
- Detect language: This option is quite good at recognizing the language from even a few words. If it does not work or if you are sure of the language, you can ease its job by selecting the right source language.
- Translation language: You may prefer using your own primary language; But remember that if you understand several others, you can sometimes try them too. A muddy translation may become clearer.
- Simply clicking on the translation may provide alternative translations. Sometimes, the second one is better for your understanding.
- Sometimes, the length of the sentence is breaking the Google algorithm. You may want to try and cut the original text in parts. It’s easy and trial-and-error is a fairly good process.
You may also remember that – by providing new translations of your own – you are helping Google getting better. One thing I personally observed as very efficient is that offering the correct translation for a technical word today, may lead to its use in further translations a few days later (any proposed translation is vetted by experts before incorporation into the internal database, but it can be quite fast – and very useful).
A few other translating options
I do not use them as often, but some other free tools are available too. Some even offer similar services and performance. I would list:
- Babel Fish (aptly named after the nearly-magical universal in-ear translator from “The hitchhiker’s guide to the Galaxy“).
- Babylon 10 (maybe related to the SciFi TV series of a few years ago, Babylon 5?)
- Bing translator
- BabelXL
Closing statements
Even with really ugly text, with imprecise comments, our team has been able to classify very efficiently horrible text into usable data.
The next stage would certainly be to start using Artificial Intelligence (maybe relying on the existing knowledge about tens of thousands of text snippets) to increase our productivity while reducing this altogether boring task. Do you know a good solution I should check now?
Leave a Reply