It is well known that the human brain has pattern matching capabilities much further advanced than those of the best equivalent software programs. This explains that failure rates of OCR (Optical Character Recognition) program may be as high as 1% (or even 2%) of errors, which is requiring later human proof-reading to ensure a reasonable quality for document scans. But when the document is old, badly printed, or degraded, error rates may climb further into the unusable (even more so when we address the scan of thousands of documents like is done by libraries and cultural institutions all over the world).
On another issue, the SPAM problem on the Internet became a major problem: Prorams try to make believe that they are human beings in order to insert advertisment anywhere a user can write (in the messages of a forum, in the comments of a blog, etc). For some time now, it became common that human users must identify themselves by their capacity to recognize a badly written word. Theoretically, this is a very efficient Turing test allowing to differentiate a human from a machine only by the results of their actions. Practically, the abilities of software programs have become so impressive that SPAM is slowly coming back again through those filters named CAPTCHAs (those images that you must read and copy back in order to be identified and approved for a specific action).
The problem appears to be: create CAPTCHA tremendously difficult for the automated software and, simultaneously, bring human beings to the task of checking scans of documents difficult to read by program.
The solution: reCAPTCHA.
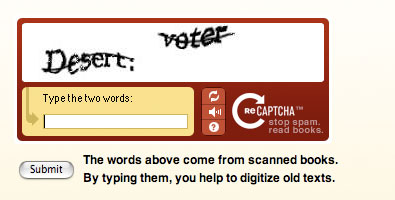
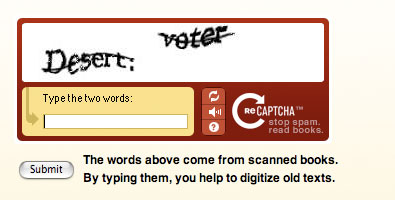
The idea is to provide a CAPTCHA service to thousands of bloggers and forum administrators (WordPress, phpBB, etc.) Users are invited to recognize two words specifically difficult to read (profesional OCR programs failed during scans done by Carnegie Mellon University). The user must recognize them both. One is used to check that this is a human being, the other will fill a database of OCR translations that will be used to deliver even more CAPTCHAs and to improve the quality of a document scanned by Carnegie Mellon. Dual core technology: efficiently fight spammers and deliver millions of human users to improve the scan quality of thousands of ancient documents (without using slave labor).
Example of a difficult to read/scan document:

One of the key advantages is that most pro OCR programs can tell when they fail to recognize a character or a word (when they are not confident enough).
Leave a Reply